九游体育app娱乐但两年后 Scaling Laws 论文发表时-Ninegame-九游体育(中国大陆)官方网站|jiuyou.com

机器之心报谈九游体育app娱乐
机器之机杼剪部
原来早在 2017 年,就进行过 Scaling Law 的考虑盘问,况且通过实证盘问考证了深度学习模子的泛化特殊和模子大小跟着窥察集鸿沟的增长而呈现出可辩论的幂律 scaling 关系。仅仅,他们其时用的是 LSTM,而非 Transformer,也莫得将考虑发现定名为「Scaling Law」。
在追求 AGI 的谈路上,Scaling Law 是绕不开的一环。
要是 Scaling Law 撞到了天花板,扩大模子鸿沟,增多算力不成大幅升迁模子的才调,那么就需要探索新的架构改进、算法优化或跨鸿沟的本事疏忽。
行动一个学术倡导,Scaling Law 为东谈主所熟知,平日归功于 OpenAI 在 2020 年发的这篇论文:

论文标题:Scaling Laws for Neural Language Models论文陆续:https://arxiv.org/pdf/2001.08361
论文中详确地论证了模子的性能会随模子参数目、数据量、狡计资源增多而指数升迁。其后的几年里,OpenAI 行动扫数这个词大模子鸿沟的本事引颈者,也将 Scaling Law 充分地踵事增华。
但对于咱们今天所评论的 Scaling law,它是若何被发现的,谁最早发现的,又是哪个团队最早考证的,似乎很少有东谈主去考据。
近日,Anthropic 的 CEO Dario Amodei 在播客中叙述了一个出东谈主意象的版块。
图源:https://xueqiu.com/8973695164/312384612。发布者:@pacificwater

咱们可能更了解 Dario 在 2016 年之后的经历。他加入了 OpenAI,担任盘问副总裁,正经公司的安全使命,并开采团队建树了 GPT-2 和 GPT-3。
但是,2020 年底,由于对 OpenAI 的发展标的产生不合, Dario 遴荐离开,并于 2021 年 2 月与妹妹共同创立了 Anthropic。
如今,Anthropic 推出的 Claude 已成为挑战 GPT 系列霸主地位的最有劲竞争者。
不外,Dario 正本的盘问标的是神经回路,他第一次信得过进入 AI 鸿沟是在百度。
从 2014 年 11 月到 2015 年 10 月,Dario 在百度使命了一年 —— 正巧是吴恩达在百度担任首席科学家,正经「百度大脑」权略的期间。
他们其时在研发语音识别系统。Dario 示意,尽管深度学习展示了很大后劲,但其他东谈主仍然充满疑虑,认为深度学习还不及以达到预期的后果,且距离他们所期待的与东谈主类大脑相匹配的框架还有很长的距离。
于是,Dario 驱动想考,要是把百度用于语音的作念得更大,增多更多的层数会若何?同期扩大数据量又会若何呢?
在束缚的尝试中,Dario 不雅察到了跟着给模子进入越多的数据、狡计和窥察,它们的发扬就越好,「那时我莫得精准地测量,但与共事们一谈,咱们相称直不雅地能感受到。」
但 Dario 和共事们也没深究,Dario 合计:「也许这只对语音识别系统灵验,也许这仅仅一个特定鸿沟的至极情况。」
直到 2017 年,他在 OpenAI 第一次看到 GPT-1 的窥察限定时,他才意志到这种「越多越好」的章程相同适用于谈话数据。而狡计资源的增多,托起了 Scaling Law 奏效的底层逻辑。
谈理是不会只属于一个东谈主的,最终它会被每个东谈主发现。
其时有一批东谈主皆意志到了 Scaling Law 的存在,比如 Ilya Sutskever、「RL 教父」Rich Sutton、Gwern Branwen。
百度也在 2017 年发了一篇论文:「DEEP LEARNING SCALING IS PREDICTABLE, EMPIRICALLY」,展示了在机器翻译、谈话建模、图像解决和语音识别等四个鸿沟中,跟着窥察集鸿沟的增长,DL 泛化特殊和模子大小呈现出幂律增长时势。
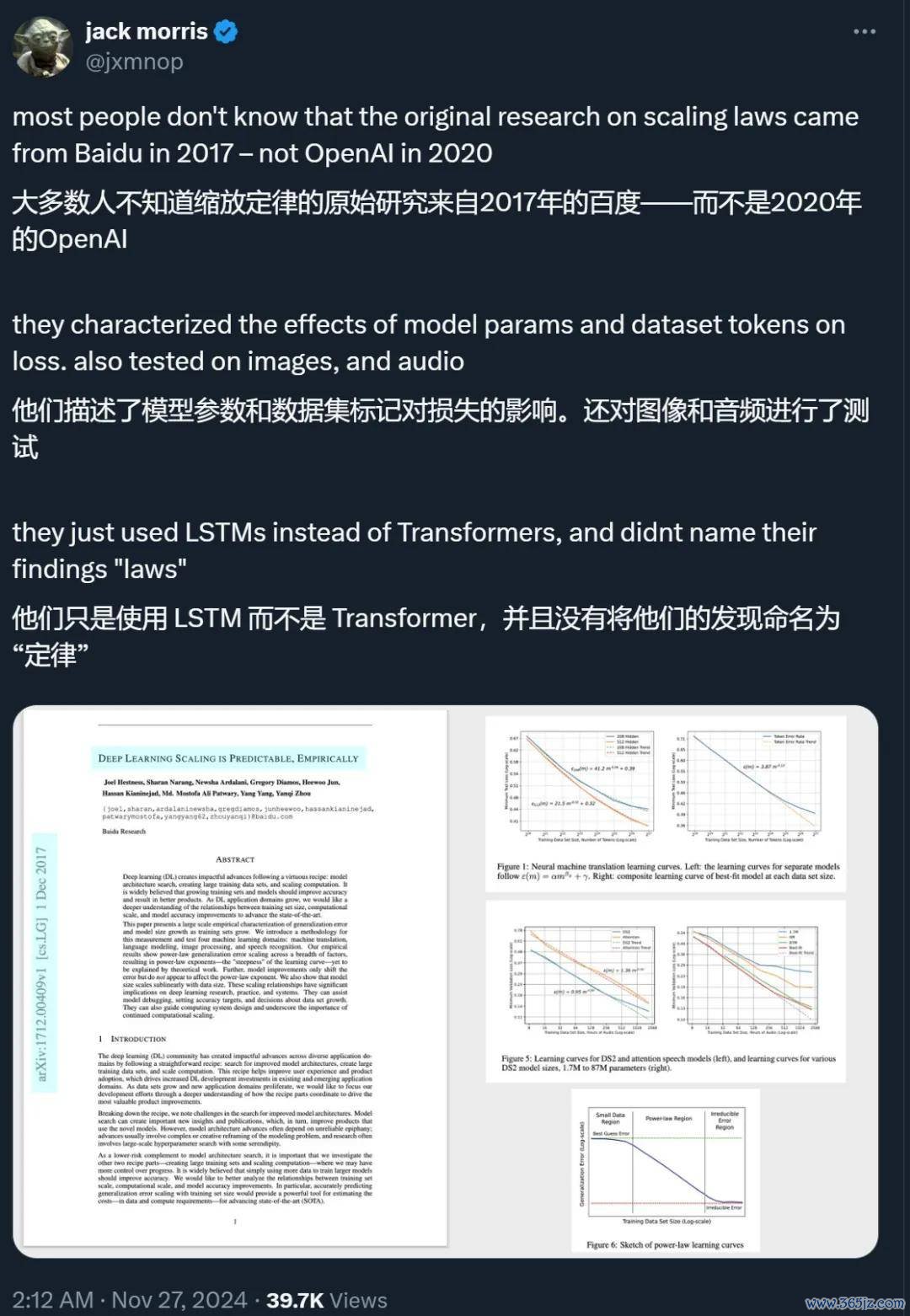
《NLP with Transformers》的作家 Lewis Tunstall 发现,OpenAI 在 2020 发表的《Scaling Laws for Neural Language Models》援用了百度论文一作 Joel Hestness 在 2019 年的后续盘问,却没发现 Hestness 早在 2017 年就盘问过同类问题。
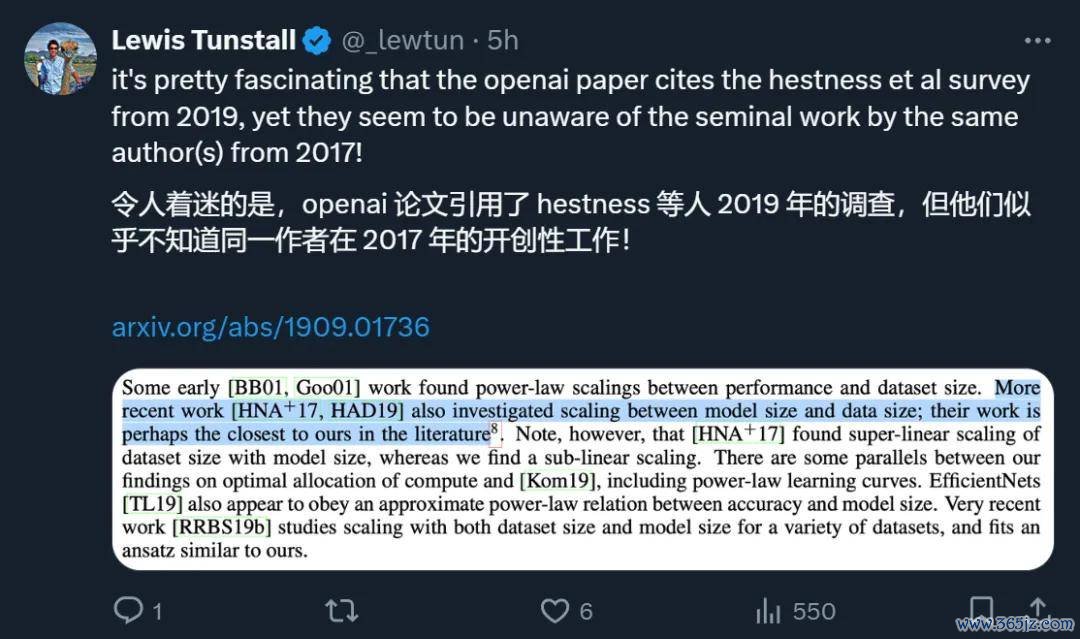
DeepMind 的盘问科学家 @SamuelMLSmith 示意,原来在 NeurIPS 和 Hestness 线下交流过。但两年后 Scaling Laws 论文发表时,他对柔软过这个问题,但没发论文的我方很不悦。
而同期细心到 Scaling Law 的 Gwern Branwen,也频繁拿起百度的这篇论文照实被冷漠了。

百度 2017 年的论文写了啥?
这篇题为「DEEP LEARNING SCALING IS PREDICTABLE, EMPIRICALLY(深度学习彭胀的可辩论性:经历性盘问)」发布于 2017 年。其时,机器学习前驱 Rich Sutton 还莫得发布他的经典著作《苦涩的透露》(发布期间是 2019 年)。

论文陆续:https://arxiv.org/abs/1712.00409
论文提到,其时,深度学习社区也曾通过解雇一个浅易的「配方」在不同的愚弄鸿沟赢得了具有影响力的进展。这个「配方」如今群众已相称熟习,即寻找更好的模子架构、创建大型窥察数据集以及彭胀狡计。
通过理解「配方」,百度的盘问者细心到,寻找更好的模子架构艰辛重重,因为你要对建模问题进行复杂或创造性的重构,这就触及大鸿沟的超参数搜索。是以,架构方面的改进许多时候要依赖「顿悟」,具有极大的未必性。要是只把元气心灵放在这上头,风险例必很高。
为了缩短风险,百度的盘问者提到,「配方」的另外两个部分 —— 创建大型窥察集和彭胀狡计 —— 吵嘴常值得去盘问的,因为这两个方面的进展光显愈加可控。而且,「只需使用更大皆据来窥察更大的模子,就能提高准确率」也曾成为一个共鸣。不外,百度想更进一步,分析窥察集鸿沟、狡计鸿沟和模子准确性提高之间的关系。他们认为,准确辩论泛化特殊随窥察集鸿沟扩大的变化法则,将提供一个宏大的器用,以揣测鼓舞 SOTA 本事所需的本钱,包括数据和狡计资源的需求。
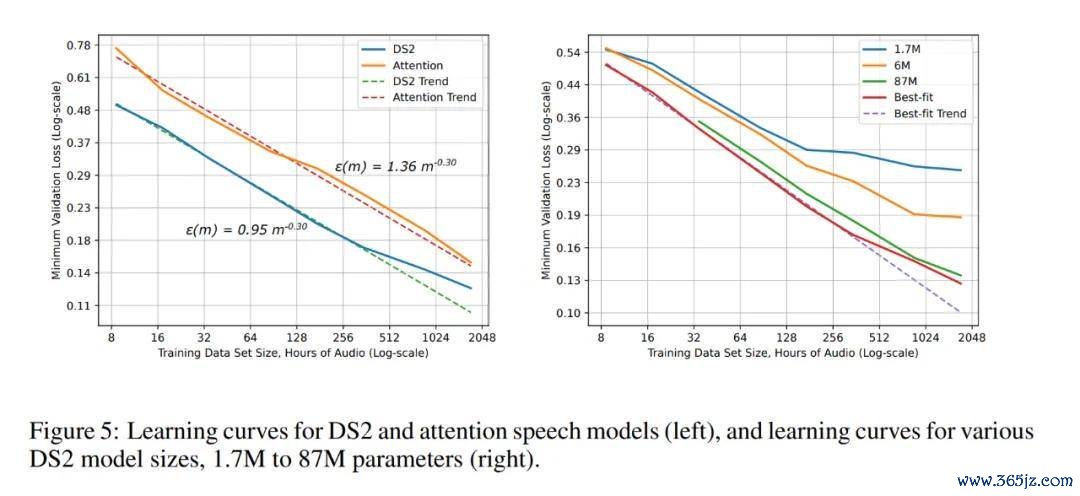
在此之前,也有不少盘问者进行了访佛盘问,分析了达到欲望泛化特殊所需的样本复杂度,但论文中提到,这些限定似乎不及以准确辩论实质愚弄中的特殊 scaling 法则。还有一些盘问从表面上辩论泛化特殊「学习弧线」呈幂律体式,即 ε(m) ∝。在这里,ε 是泛化特殊,m 是窥察聚积的样本数目,α 是问题的一个常数属性。β_g= −0.5 或−1 是界说学习弧线陡峻度的 scaling 指数 —— 即通过增多更多的窥察样本,一个模子家眷不错多快地学习。不外,在实质愚弄中,盘问者发现,β_g 平日在−0.07 和−0.35 之间,这些指数是先前表面使命未能解释的。
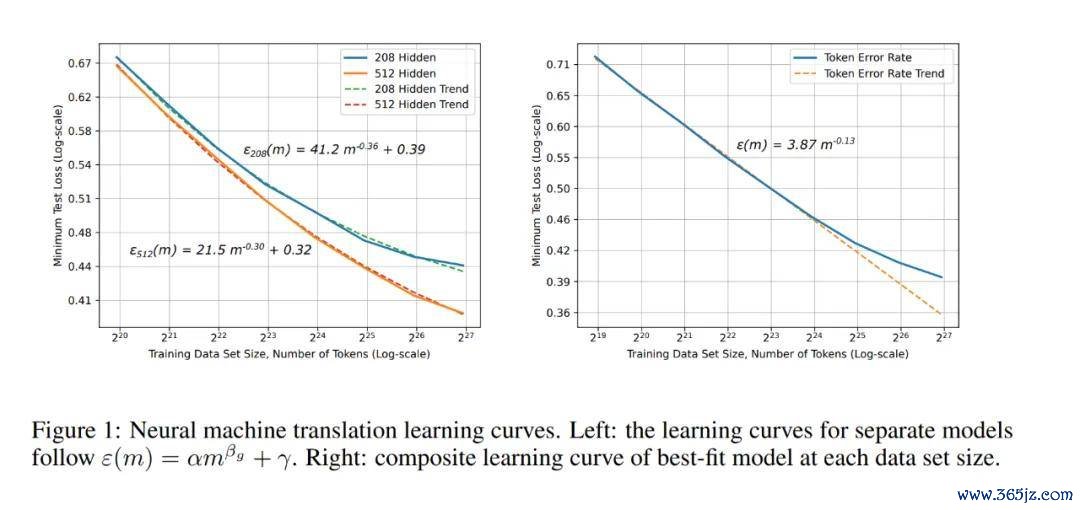
在这篇论文中,百度的盘问者建议了其时最大鸿沟的基于实证的学习弧线特征形色,揭示了深度学习泛化特殊照实显泄露幂律改动,但其指数必须通过实证进行辩论。作家引入了一种圭臬,能够准确辩论跟着窥察集鸿沟增多而变化的泛化特殊和模子大小。他们使用这种圭臬来揣测四个愚弄鸿沟(机器翻译、谈话建模、图像分类和语音识别)中的六个深度神经集聚模子的 scaling 关系。
他们的限定浮现,在扫数测试的鸿沟中皆存在幂律学习弧线。尽管不同的愚弄产生了不同的幂律指数和截距,但这些学习弧线起首了平凡的模子、优化器、正则化器和亏蚀函数。改动的模子架构和优化器不错改善幂律截距,但不影响指数;单一鸿沟的模子显泄露疏浚的学习弧线陡峻度。终末,他们发现模子从小窥察集区域(主要由最好料到主导)过渡到由幂律 scaling 主导的区域。有了弥漫大的窥察集,模子将在主要由不可约特殊(举例贝叶斯特殊)主导的区域达到饱和。
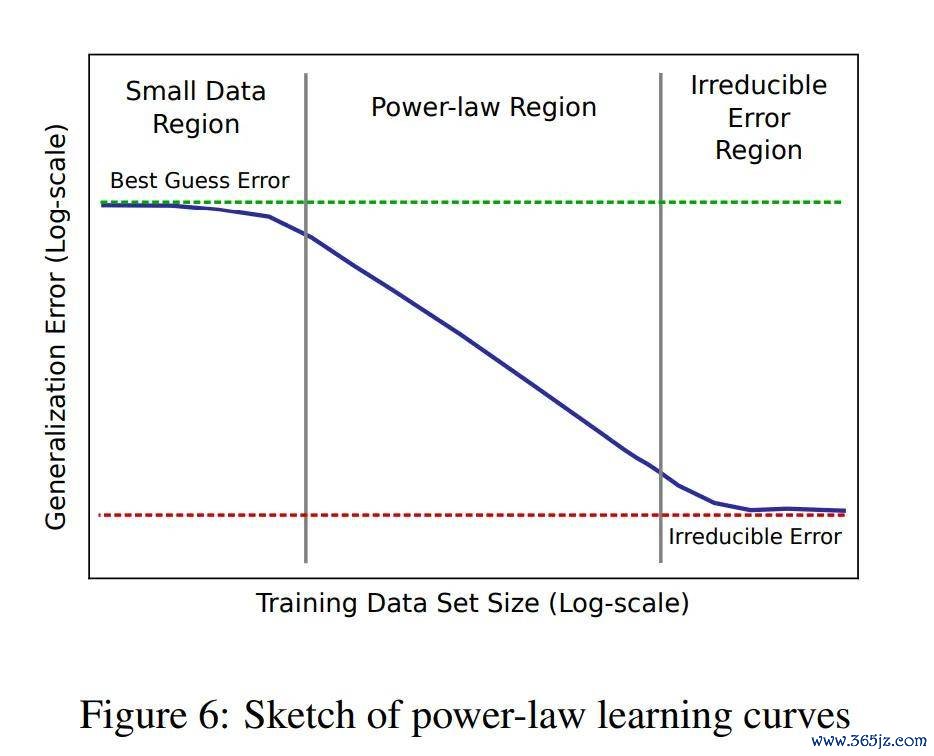
此外,他们还形色了可辩论的准确度和模子大小 scaling 的进军谈理。对于深度学习从业东谈主员和盘问东谈主员来说,学习弧线不错匡助调试模子,并为改动的模子架构辩论准确性想法。
百度的盘问者在论文中示意,他们的盘问限定标明,咱们有契机加倍起劲,从表面上辩论或解释学习弧线指数。在操作上,可辩论的学习弧线不错携带一些有盘算推算,如是否或如何增多数据集。终末,学习弧线和模子大小弧线可用于携带系统假想和彭胀,它们强调了合手续彭胀狡计的进军性。
神经机器翻译学习弧线。
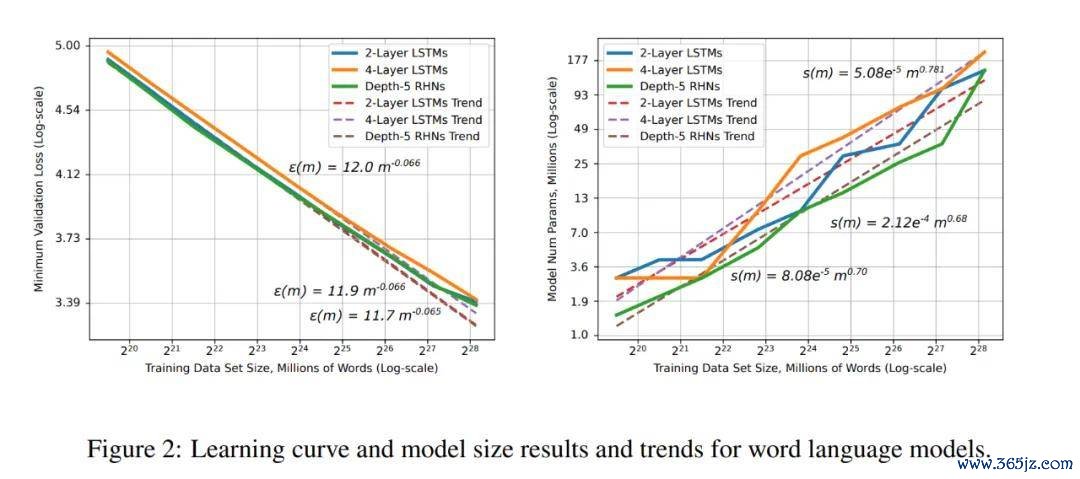
单词谈话模子的学习弧线和模子大小限定和趋势。
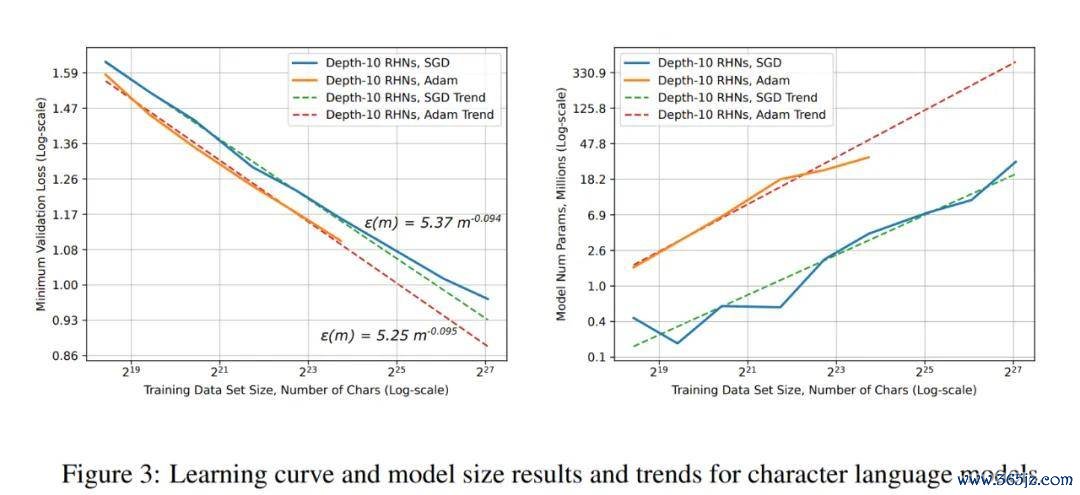
字符谈话模子的学习弧线和模子大小限定和趋势。
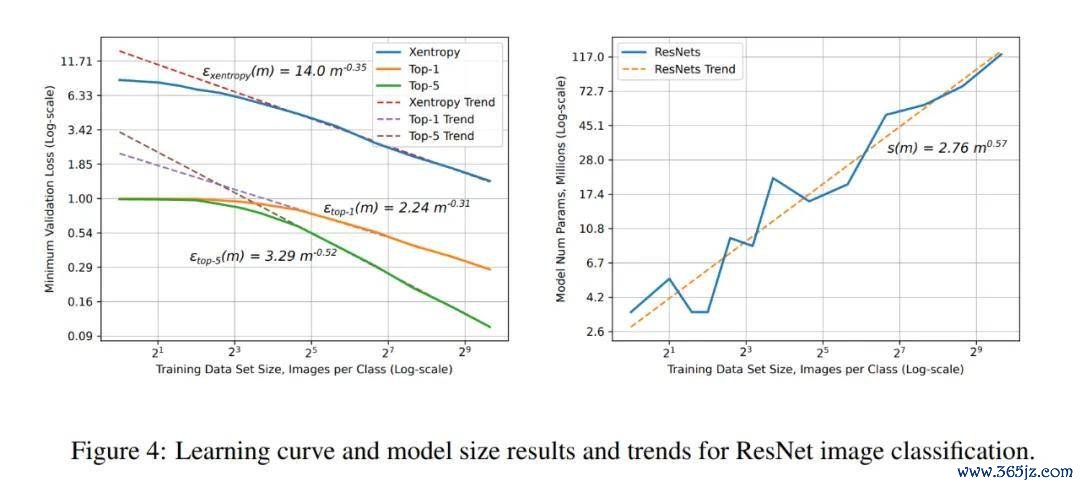
ResNet 图像分类任务上的学习弧线和模子大小限定和趋势。
DS2 和细心力语音模子的学习弧线(左),以及不同 DS2 模子尺寸(1.7M ~ 87M 参数)的学习弧线(右)。
对于百度而言,早期对 Scaling Law 的盘问未能实时滚动为平凡的现实愚弄,这在公司的发展史上简略算得上是一个不小的缺憾。
https://x.com/jxmnop/status/1861473014673797411
https://arxiv.org/abs/1712.00409



